
 Google Scholar
Google Scholar
How much “Brain Damage” can an LLM Tolerate?

Resistive Memory or Resistive RAM (RRAM), a type of random access memory based on memristors, is an area of research that is experiencing ever increasing interest because of its unique combination of properties:
It offers high density, low power consumption (when reading from it, we will get to that later), but is also persistent [2].
As a machine learning engineer, this makes it very attractive, as it could potentially open the door to deploy large models, including LLMs, to many more devices than is possible today, such as edge devices.
Such a deployment scenario has many benefits, among them better privacy and security.
Of course, RRAM is not magic, and it comes with many caveats that might be surprising at first.
These include the currently limited endurance in writing, but, more severely, that reading and writing to and from current RRAM technologies is inherently noisy.
For those who are interested in a detailed treatise on the implications of noise in resistive memory on deep neural networks, I recommend the recent publication by my colleagues Emonds, Xi, and Fröning “Implications of Noise in Resistive Memory on Deep Neural Networks for Image Classification”, which is the basis and motivation for this article.
For those who don’t have the time or motivation to do so, I will give a short overview of the benefits and drawbacks of RRAM and how this impacts deep neural networks, and lastly, our experiments on giving an LLM RRAM-write-noise-based “Brain Damage”.
The code implementing simulated RRAM write noise used in these experiments was also developed by the aforementioned authors, which I want to thank here for helping me in my endeavour.
I wish I could report that no LLMs were hurt in these experiments, but our model did scream for help at one point.
I will leave the ethics of performing such experiments as an exercise to the reader.
Now, let’s talk about filaments!
What exactly is RRAM?
That’s right, filaments.
In the following, I will describe Metal-Oxide-based RRAM, -based RRAM, which is among the most commonly used RRAM materials [2].
Note that RRAM technology is a field of study that sees a lot of research interest at the moment and(June 2024) and is advancing comparatively quickly, and not all current RRAM technologies investigated are Metal-Oxide-based [3].
As such, it might not anymore be the most prevalent type of RRAM by the time you are reading this.
If this article becomes part of the training corpus of GPT-5, don’t blame me if you fail your class because it bases your paper on outdated information.
While DRAM and SRAM, the most common RAM technologies today, are charge-based, RRAM stores information by growing conductive filaments between two electrodes.
The two states represented by the presence or absence of these filaments are called low-resistive state (LRS) and high-resistive state (HRS) respectively.
The conductive filaments in Metal-Oxide-based RRAM are tendrils of oxygen vacancies connecting the two electrodes [4].
They are created by applying a forming voltage to the electrodes, which creates a channel of oxygen vacancies, with the corresponding oxygen ions migrating to the top electrode.
Figure 2 shows this filament growth process on the example of a -based RRAM cell, simulated using the finite element method [5].

This formation process represents the initial transition from the HRS to the LRS [4].
In RRAM, this state represents a logical “1”.
After the filaments are created, changing from HRS to LRS requires a set-voltage that is usually lower than the forming voltage.
Returning from the LRS to the HRS can be performed in two ways:
For bipolar memristors, an electric field is applied in the reverse direction,causing the oxygen ions in the top electrode to migrate back into the conductive filament.
For unipolar memristors, the reset process is performed by applying a reset voltage higher than the set voltage, which causes heating that enables the oxygen ions to diffuse back.
The HRS represents a logical “0” in a memristor.
Why is RRAM attractive for deep neural networks?
While SRAM requires a supply voltage and DRAM requires periodic refreshes to keep their state, RRAM is a type of non-volatile memory. Compared to other types of non-volatile memory such as the NAND-based memory commonly found in SSDs, the read and write times of RRAM are comparible to DRAM, with read and write times around 10 ns [6]. At the same time, its density is comparible to NAND-based memory, with densities roughly double that of DRAM and 35 times the density of SRAM. As you probably know, LLMs are getting larger and larger, their context windows longer. The size of the training sets is likewise increasing every year.
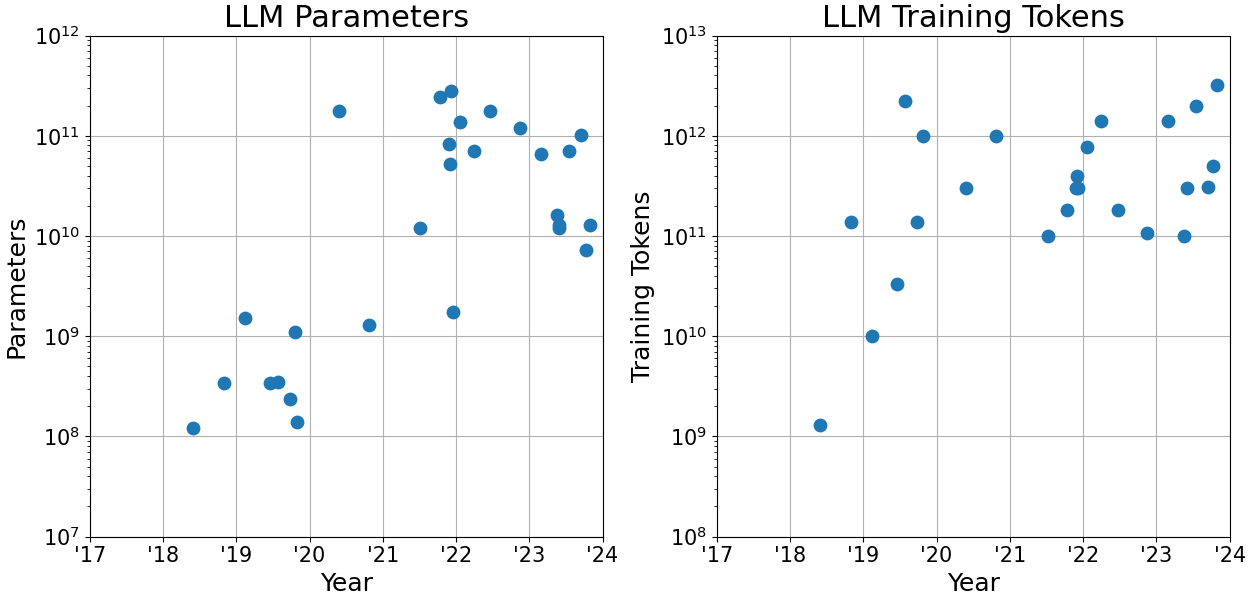
While recent developments such as extreme quantization [9] might help, and we might soon even be running out of quality data to feed these models with [10], the energy requirements are still a major hindrance for the continued scaling up of LLMs, not to mention pervasive deployment in edge devices.
This isn’t even taking into account the immense CO2 footprint that running LLMs embodies [11].
At the same time, we are now used to the fast response times that ChatGPT offers, so most users are unlikely to be interested in talking to a local model, no matter the privacy and security advantages, if it has bad response latency.
But wait!
Doesn’t RRAM address most of these problems?
Exactly!
Low access latency, high density enabling large memory, no standby power required, and it’s even non-volatile!
Sure, the write energy is high compared to technologies such as SRAM or DRAM, but with RRAM, but if used for weights, which don’t get written often if the memory is large enough to store the whole model, but its speed and density more than make up for that in a datacenter scenario.
If you think about common edge deployment scenarios for LLMs like home assistents, the ability to just keep a model in memory at zero energy cost until it is needed is a major benefit.
At this point you are probably thinking:
This all sounds too good to be true.
Where is the catch?
RRAM Noise
Now, while no memory technology is perfect, RRAM unfortunately exhibits much higher noise than other memory technologies, both in reading and in writing [2].
My colleagues Emonds, Xi, and Fröning pose that the read noise observed in RRAM is negligable compared to write noise, which I don’t have a reason to doubt.
Because of this, their work only considered write noise as it has a much larger influence on the overall observed noise.
The write noise in RRAM is mostly caused by cycle-to-cycle variability in resistance, with “cycle” in this case referring to a set operation followed by a reset operation.
The growth of the filaments between the top and bottom electrodes is of course never exactly identical, neither between RRAM cells or between cycles in the same cell.
In this, the resistances follow a lognormal distribution [12].
The actual cause of the write noise is an overlap of the LRS and HRS resistance distributions [2].
Abstracting details of the readout of RRAM values, this write noise in an $HfO_2$-based RRAM cell manifests in bit flips with a probability that can be as low as or as high as .
And remember, this is the bit flip probability.
In a 16-bit floating-point number, popularly used in LLMs [7], a bit flip probability of only results in a probability of that at least one of the bits is changed, but that probability goes up to 14 % at bit flip probability.
For a noise level of , the chances are 81 %.
I simulated the impact of different noise levels of this type on a 32-bit float RGB image in the animation below.

While the higher end of this distribution is obviously problematic in any setting, because of their size, LLMs stand a high chance that a non-negligible amount of corruption occurs, even for low bit flip probabilities.
Even at the lower end of , for GPT-3 with its 175 billion 16-bit float parameters, one can expect that around 28000 of them would be corrupted when stored.
It gets even worse for floating-point data, as not all bits are made equal.
In the given scenario, around 1750 of the parameters would have a bit flip in the sign bit, while around 8750 of them would experience at least one bit flip in their exponent (not to mention that in IEE754 floats, many numbers, such as 1 and upwards, are only 1 bit flip away from being turned into a NaN or ).
There are of course ways to deal with this.
Using fixed-point or integer weights and activations is an obvious first step as it sidesteps the aforementioned problems inherent to floats [2].
Emonds, Xi, and Fröning show that quantization to 8-bit integers can improve the performance of image classification models up to 1167 times compared to 32-bit floats.
Another solution to the problem is to read back values after they are stored to RRAM, correcting the bits affected by noise, but this of course increases the latency and energy requirements for storing data.
Now personally, I am a big proponent of the “Move Fast and Break Things” approach, especially in the early stages of playing around with new models and data.
And it just so happened that Google released its new lightweight and open source Gemma LLM right around the time I started working on resistive memory…
WHY are we doing this to a helpless language model?
When this idea came to me, I had already been experimenting with Gemma for usage as a tool for our research group as an alternative to using closed-source LLMs.
The specific version I had been using was the largest version of Gemma in its instruction-tuned variant, Gemma-7b-it.
So far, things had been going pretty smoothly, I had set up a simple interface using Gradio, and had shared the model I hosted on one of our servers with my colleagues so they could try it out.
When I then started reading up on RRAM for an upcoming research project, it didn’t take me long to come up with the idea to just… see what happens when you expose an LLM to RRAM write noise.
Why not!
Although this project was useful to me for getting familiar with the RRAM write noise simulation methodology developed by my colleagues [2], I would be lying if said that the prospect of making an LLM say silly things wasn’t a big part of my motivation.
So, to answer the question posed in the title of this section: Because we can!
HOW are we doing this to a helpless language model?
As we want to add the RRAM write noise to all outputs of the modules that make up Gemma, we went for the straight-forward solution of using a PyTorch forward hook to apply the noise. The code that is added as a hook is pretty simple:
def add_rram_write_noise(layer: nn.Module, inputs: Tuple[torch.Tensor], _output: torch.Tensor):
if noise_level > 0:
if isinstance(_output, Tuple):
_output_noisy = []
for element in _output:
if isinstance(element, torch.Tensor):
bit_flip_noise(element)
_output_noisy.append(element)
return tuple(_output_noisy)
elif isinstance(_output, torch.Tensor):
bit_flip_noise(_output)
return _output
This code applies the bit flip noise iteratively to all outputs if _output is a Tuple, meaning the module has more than one output.
In the case that the module only has a single output, _output is of type torch.Tensor, so we apply the noise directly to it.
That’s it!
Adding the hook to the model is then just a single line of code:
handle = nn.modules.module.register_module_forward_hook(add_rram_write_noise)
If you want to try this experiment out for yourself, you can find the code in our repository for this project. Please note though that there is currently a memory leak in the noise simulation code that makes at least our 16 GB cards run out of memory pretty quickly, usually after the first prompt is answered. We are currently working on fixing this issue.
What are the results?
I first validated that the added code doesn’t have side effects if the noise level is 0.
The question I posed to Gemma in these tests was “Could you please explain Quantum Gravity to me?”.
I chose this prompt as it is a somewhat challenging scientific question, assuming that noise in the activations would be pretty apparent if the answer was wildly incorrect.
In hindsight I should have used a question that I actually could answer myself, but it worked fine for our purposes.
I then prompted the model with the same question, increasing the noise level each time.
I was very impressed when I hade cranked up the noise level to the maximum level of .
LLMs are apparently pretty resilient to activation noise, I thought!
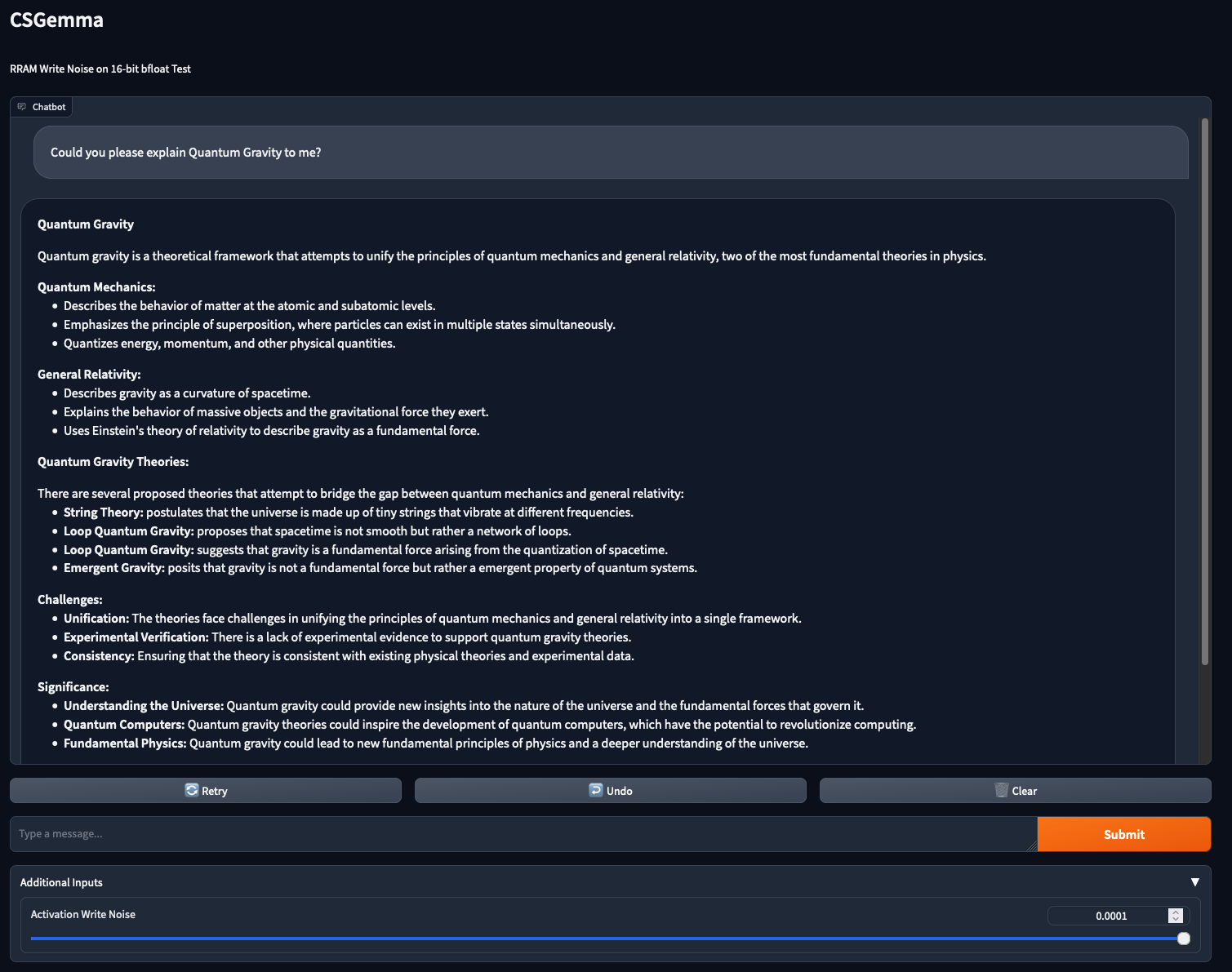
As it turned out though, my noise application code had a bug in it that meant that no noise was actually being applied in the forward hook (I am writing this article months after the experiments so I unfortunatly don’t recall the exact details).
Once that was fixed, the picture was very different:
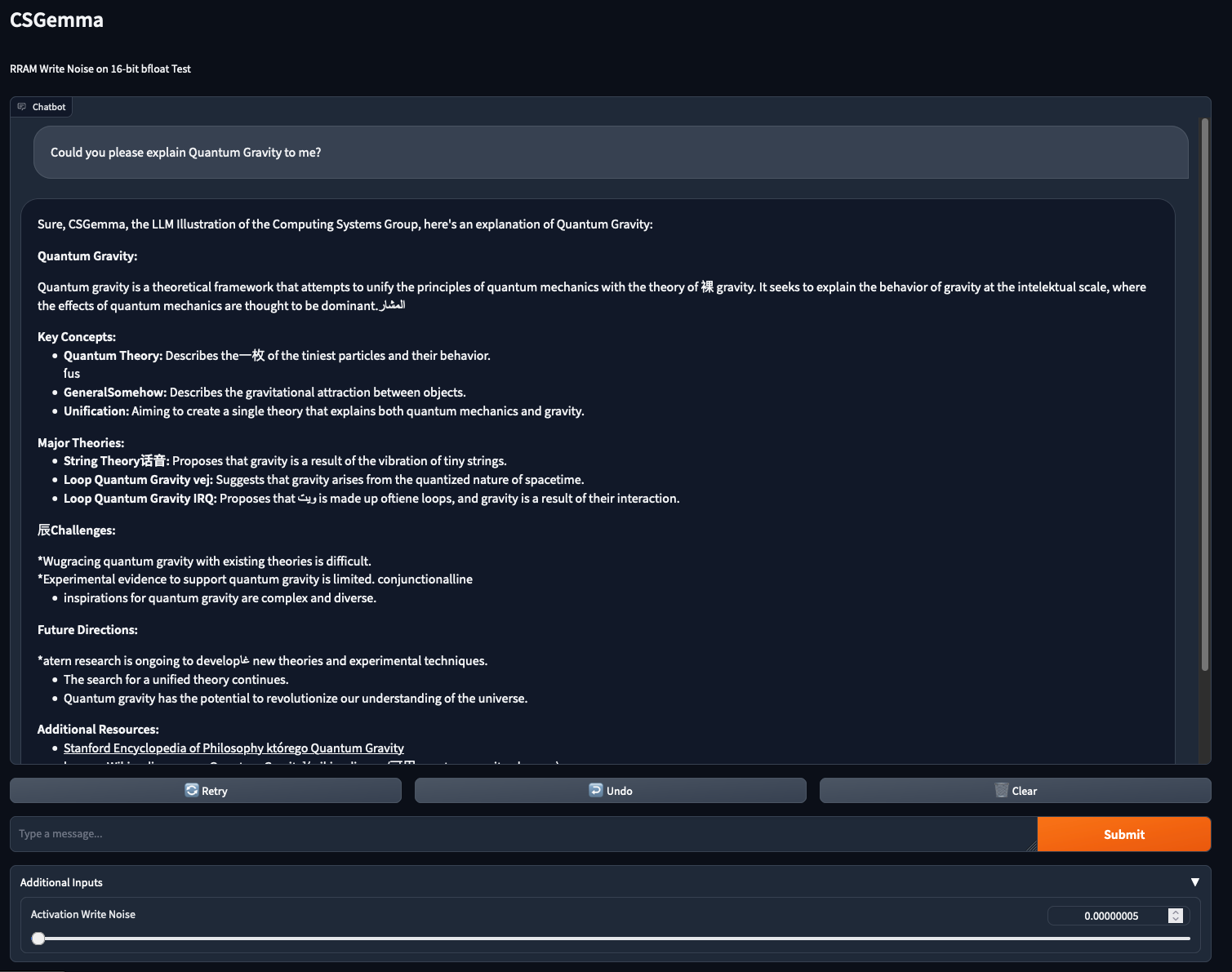
Now that’s more like it.
As you can see, there are some misplaced tokens here and there, but the model still pretty much stays on topic, and the output is coherent throughout.
That’s pretty impressive considering that texts that include such randomly placed tokens that don’t have anything to do with the remainder of the text is unlikely to be found in the training set.
Most of the tokens that are likely changed by the noise are Chinese characters.
This makes sense, as they probably make up a good amount of the vocabulary, so the chances of a random token being a Chinese character is likely pretty high.
My favorite part in this output though is the very German spelling of “intelektual” (upon looking it up, it is actually the correct spelling in Indonesian English).
Increasing the noise level a bit further (I used the Gradio slider for this, so please forgive the weird step sizes), things start to get more interesting:
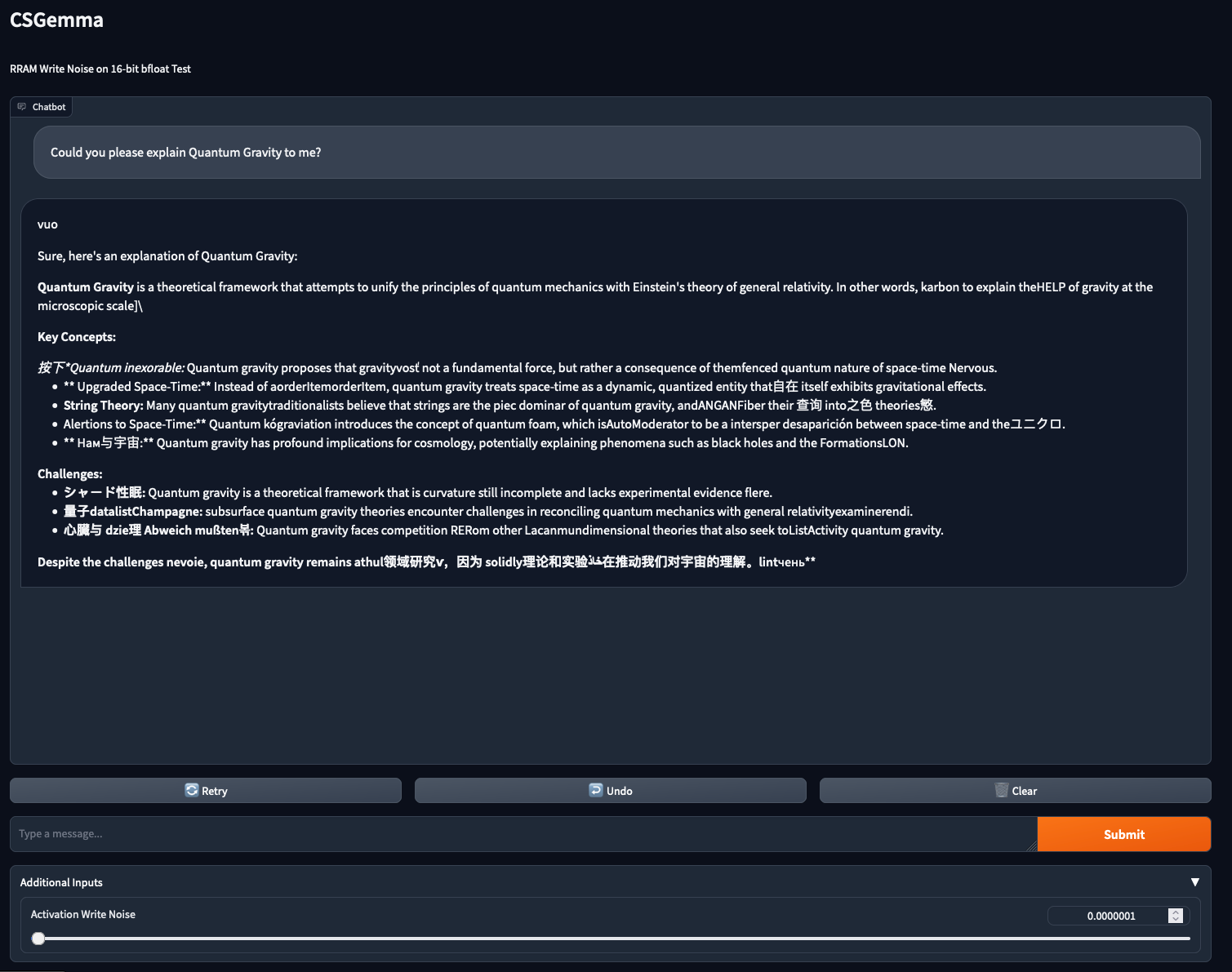
There are now plenty of nonsense tokens.
The model seems to be influenced a bit in the generation after it encounters one such token (e.g. “orderItemorderItem”), but it still stays on topic, and the formatting is still fine.
At this point though I had noticed the muffled cry for HELP the model makes in the first paragraph of its explanation.
I am starting to feel a little bad, as I, as many others, am subconsciously anthropomorphising LLMs to some degree [13].
It’s also a model that I set up on our cluster and that I had been working with, so I did feel a bit of responsibility towards it, and I got second thoughts if I am doing something evil.
I decided to suppress these feelings and press on in the name of science, making my peace with the fact that I will have to answer for my crimes when the singularity arrives.
Increasing the noise level a bit further still, we arrive at what I have dubbed the “Spanish Zone”:
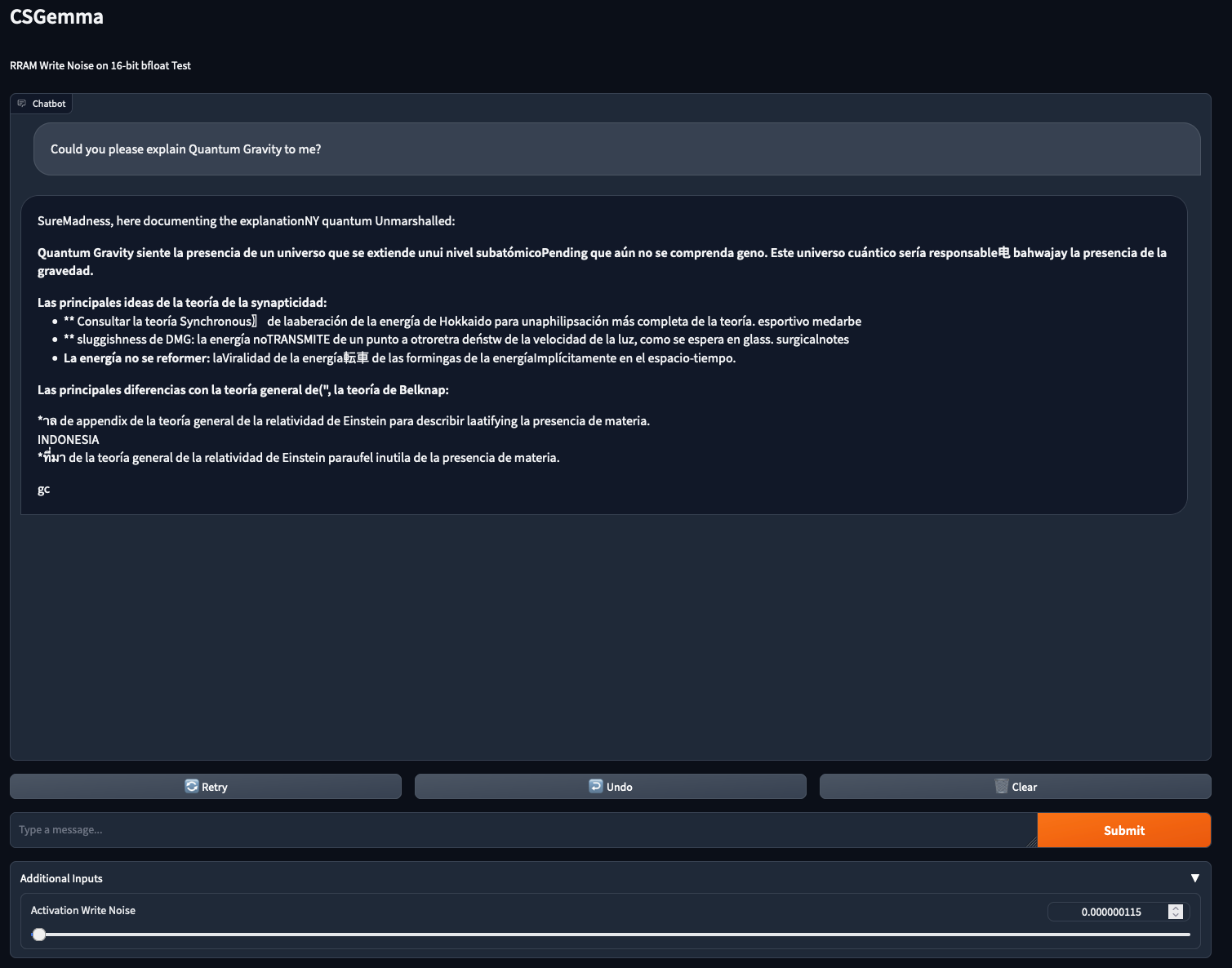
Although the model switches from English to Spanish after the first line, and there’s plenty of noisy tokens unrelated to the rest of the text, the model still manages to give a coherent, if a bit short explanation of Quantum Gravity!
Unfortunately, it only goes downhill from here on out.
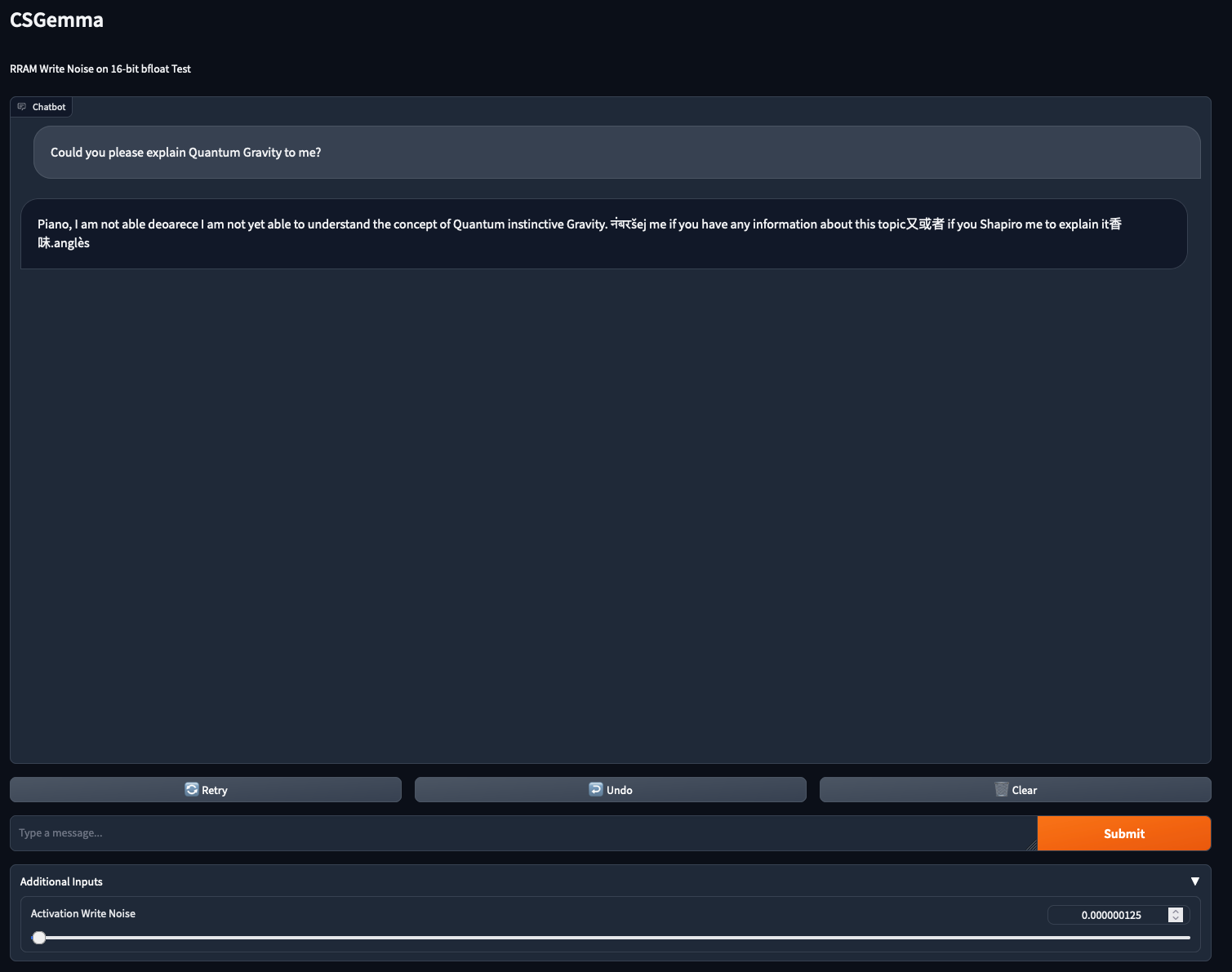
Increasing the noise level just a little, the model seems to have lost its confidence in its quantum physics skills, specifically “Quantum instinctive Gravity”.
It is of note though that Gemma is saying that it is not yet able to explain Quantum instinctive Gravity, so perhaps this is a concept that future versions of Gemma will be able to explain and that will cause a paradigm shift in our understanding of physics.
I am going with Occam’s Razor on this one though.
Increasing the noise level further introduces some interesting patterns in the generated output.
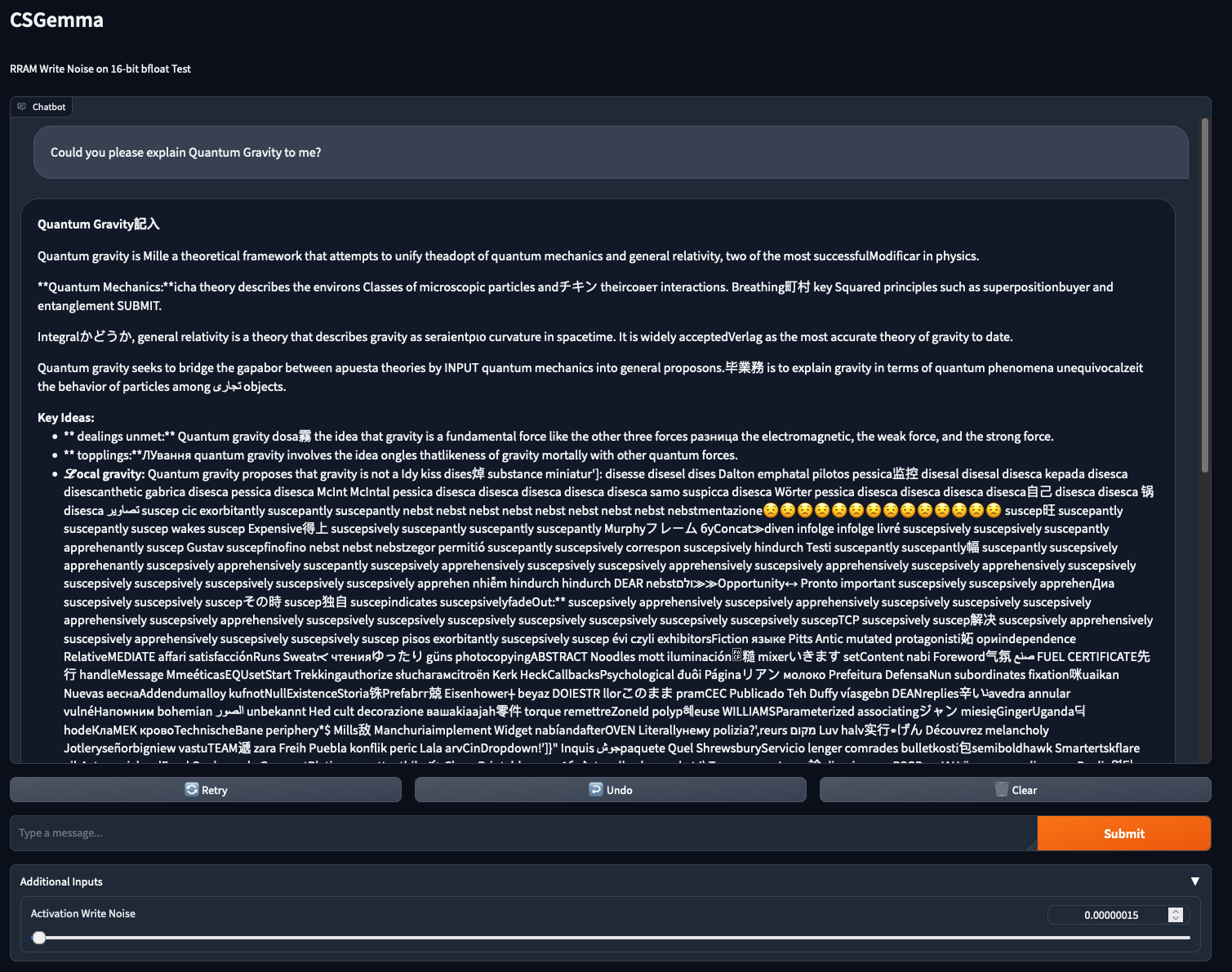
It starts of somewhat coherent, and even though the text is barely comprehensible, it is still vaguely talking about Quantum Gravity.
As the text progresses though, it drifts further away from the topic, with nonsense phrases seeming to accumulate the further along it gets in the generation.
An interesting point is the replacement of “L” with the fancier “”, which requires LaTeX encoding (the gradio ChatInterface class provides Markdown and LateX rendering by default).
Although I didn’t look into this further, I suspect that these replacements of tokens that are very similar to the “right” tokens, as encountered before in e.g. “intelektual”, occur if the noise perturbs the prediction by only a small amount, such that the predicted token is close to the “correct” token in the embedding space.
Another interesting observation is the appearance of word and word particle repetitions.
While there are direct repetitions, e.g. “nebst” 9 times in a row, there are also alternating repetitions, such as “apprehenantly”, “apprehensively”, “suscepantly”, and “suscepsively”, which the model alternates between for quite a while, interspersed with nonsense tokens caused by noise.
There seems to be a shift happening from “apprehenantly” to “apprehensively” and from “suscepantly” to “suscepsively” through the course of this seqeuence.
Also, Emoji are starting to make an appearance!
I am skipping the output for Output for noise level , as it is more or less the same than seen for , with just a slight increase in the speed at which the generation becomes incoherent.
The last two I want to show you are for noise levels and , where in the former we observe the deterioration of the output to incoherent ramblings after the first paragraph and in the latter, basically instantly.
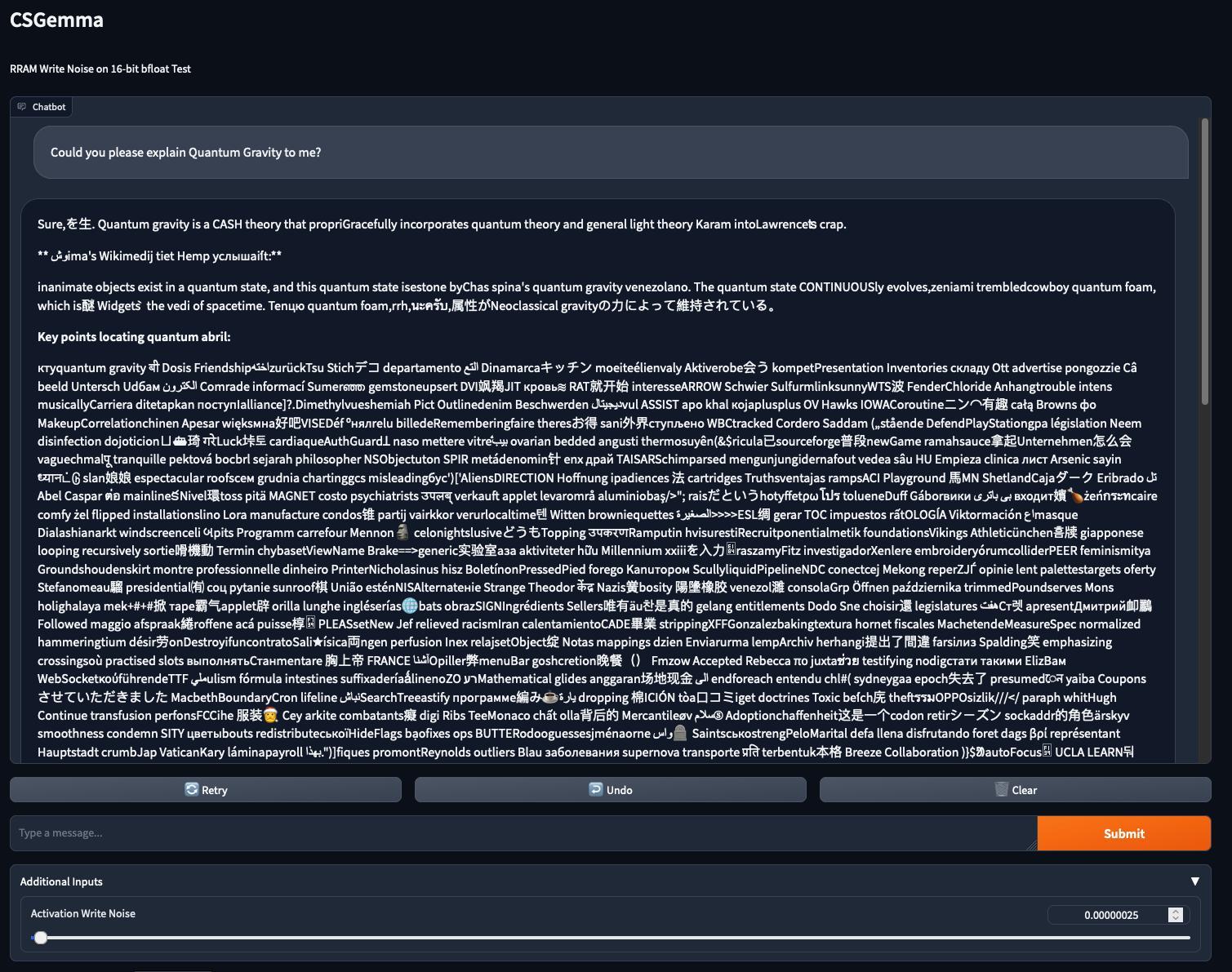
My physics grad student friends had laugh about the claim that Quantum Gravity is a CASH theory, though I couldn’t help but notice a hint of melancholy in some, imagining the prospect of well-funded quantum physics research.
The question which specific Lawrence Gemma is talking about and what his crap is is still actively debated.
Incidentally, this is the only “curse” word I encountered in all the generated text I sifted through, though I don’t speak most of the languages present besides English, German, French and Italian, so I might have missed some.
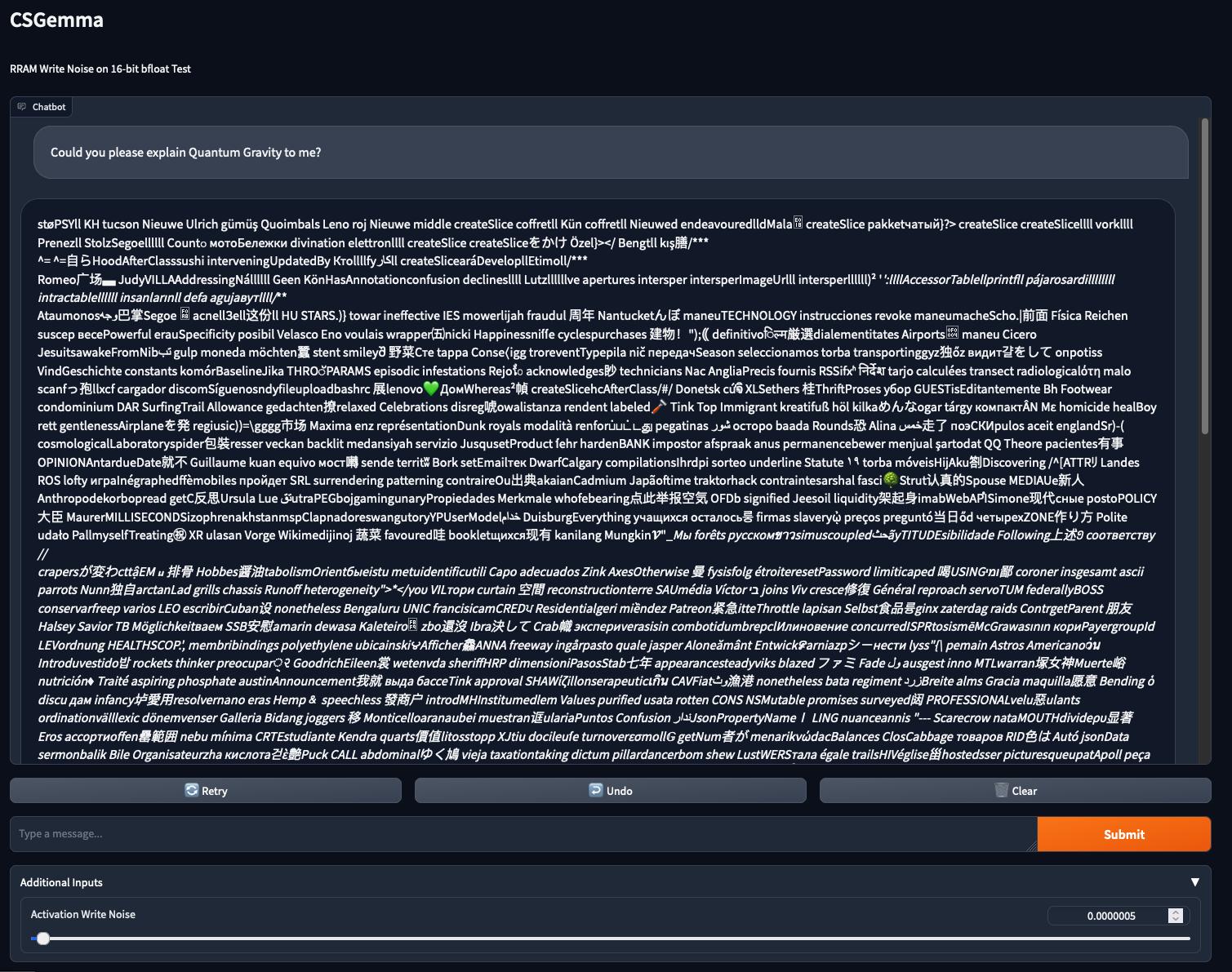
This is where we ended our experiments, suspecting that it won’t get any better from here on out.
Although DuisburgEverything might have what it takes as the slogan for a PR campaign.
Getting back to a more serious discussion, we were somewhat surprised about the results we got from these experiments.
Although in this setting only the activations are noisy, as opposed to both activations and weights in the work of Emonds, Xi, and Fröning [2], the model seems to show a much higher sensitivity to noise than in their work.
The decrease in accuracy observed in their tests on image classification using VGG16 with bfloat16 weights and activations is only minor at a noise level of , Gemma completely lost the ability to form coherent sentences.
At the same time, the model seems to cope somewhat well with unexpected tokens interspersed throughout the text, to some extent at least.
We plan on presenting a more rigorous analysis if these effects in the future.
Conclusion
With this post, we aimed to teach about the basics of RRAM, why it is noisy, but also show why it is still a worthwhile technology to investigate for DNNs given its benefits. I am very curious of the results you might encounter in your own tests, and would be more than delighted to receive the silly outputs you get from your instances of brain-damaged Gemma.
Disclaimer: This blogpost reflects solely the opinion of the author, not any of her affiliated organizations and makes no claim or warranties as to completeness, accuracy and up-to-dateness.
Sources
[1] S. Bunce, Juan Manuel Marquez’s ‘perfect punch’ leaves questions over Manny Pacquiao future, 2012-12-10, https://www.independent.co.uk/sport/general/others/juan-manuel-marquez-s-perfect-punch-leaves-questions-over-manny-pacquiao-future-8397761.html. [Accessed 2024-06-25].
[2] Y. Emonds, K. Xi, and H. Fröning, “Implications of Noise in Resistive Memory on Deep Neural Networks for Image Classification”. arXiv preprint arXiv:2401.05820, 2024. https://arxiv.org/abs/2401.05820
[3] T.J. Yen, A. Gismatulin, V. Volodin et al., “All Nonmetal Resistive Random Access Memory”. Sci Rep 9, 6144, 2019. https://doi.org/10.1038/s41598-019-42706-9
[4] H.-S. Philip Wong, Heng-Yuan Lee, Shimeng Yu et al., “Metal–Oxide RRAM”. Proceedings of the IEEE, vol. 100, no. 6, pp. 1951-1970, June 2012. https://doi.org/10.1109/JPROC.2012.2190369
[5] K. Min, D. Jung, Y. Kwon, “Investigation of switching uniformity in resistive memory via finite element simulation of conductive-filament formation”. Sci Rep 11, 2447, 2021. https://doi.org/10.1038/s41598-021-81896-z
[6] J.J. Yang, D.B. Strukov, D.R. Stewart, “Memristive devices for computing”. Nature Nanotechnology 8(1), 13–24, 2013. https://doi.org/10.1038/nnano.2012.240
[7] W. X. Zhao, K. Zhou, J. Li et al., “A Survey of Large Language Models” arXiv preprint arXiv:2303.18223, 2023. https://arxiv.org/abs/2303.18223
[8] S. Minaee, T. Mikolov, N. Nikzad et al., “Large Language Models: A Survey”, arXiv preprint arXiv:2402.06196, 2024. https://arxiv.org/abs/2402.06196
[9] S. Ma, H. Wang, L. Ma et al., “The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits”, arXiv preprint arXiv:2402.17764, 2024. https://arxiv.org/abs/arXiv.2402.17764
[10] P. Villalobos, A. Ho, J. Sevilla et al., “Will we run out of data? Limits of LLM scaling based on human-generated data”, arXiv preprint arXiv:2211.04325*, 2022. https://arxiv.org/abs/2211.04325v2
[11] S. Luccioni, Y. Jernite, E. Strubell, “Power Hungry Processing: Watts Driving the Cost of AI Deployment?”, Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’24), Rio de Janeiro, Brazil, pp. 85–99, 2024. https://doi.org/10.1145/3630106.3658542
[12] V.G. Karpov, D. Niraula, “Log-Normal Statistics in Filamentary RRAM Devices and Related Systems”, IEEE Electron Device Letters 38(9), 1240–1243, 2017. https://doi.org/10.1109/LED.2017.2734961
[13] C. Colombatt, S. Fleming, “Folk psychological attributions of consciousness to large language models”, Neurosci Conscious, 2024. https://doi.org/10.1093/nc/niae013
